Obsidian_使用阿里OSS图床
前言
写篇笔记总结下今天花费4小时的成果
不想看啰嗦的可以直接跳到OSS 搭建开始进行阅读
讲讲目前发现的一个remotely-save插件的Bug
也算是今天搭建图床的起因吧
今天在手机端使用remotely-save对Obsidian进行同步的时候,突然闪退掉
尝试了几次都是如此,查阅了下相关资料(remotely-save仓库的issute和论坛),详见参考资料
排查了下是有个笔记的gif60M左右,确实如参考资料1.1所说,问题出在:大于30M同步会导致闪退
目前属于插件问题,nodejs和TypeJS这两块知识面暂时不足,所以不能够对插件基础上进行维修,所以对于插件无解
目前的解决方法
- 使用图床
- 大文件手动迁移下,毕竟大于30M的图片还是比较少的,可以使用
localsend_app或者HandShaker进行电脑手机联动,这里就不提供下载链接了,大伙自己搜索下
之前一直没想要采用图床,因为要对我现有的工作流程做很大改动,很耗费时间,不是很想改动(懒),像今天就耗费了4小时多才弄完
今天出问题了,索性当断则断整改了
方案有了,罗列下问题(对应目录)
Obsidian图片如何转图床链接(Obsidian使用图床)Typora如何设置图床(Typora使用图床)- 现有同步脚本如何修改
Obsidian——>Hexo,也耗费了些精力,但属个人工作流,对他人没有借鉴意义,所以不会出现这篇教程中
- 延伸:如何删除图床中未引用的图片?(清理图片)
图床与本地
从几个角度讲讲图床和本地,大伙看情况抉择
隐私性
图片存储在库中确实很方便,但Obsidian库中的图片,实际是会出现在手机的相册中
而手机的一些应用(或者说大部分应用)都会获取文件的读写权限,意味着可以直接读写这些文件
我有些图片涉及ID、Key、身份证、个人信息等,包含大量个人隐私信息,这么做相当于对这些应用是完全开放另外我有考虑手机丢失的情况
如果丢失虽然有加应用锁,但是刷机的可以打开手机后,通过相册间接看到这些信息
而采用OSS,本地则不会有这些图片
当然丢失是最坏的情况离线
采用OSS必须完全有网络,才可以看图
而本地,没网一样可以看费用和安全性
采用OSS虽然不贵,但是还是要缴费
另外要注意安全性,暴露到公网可能会给其他人盗刷,间接破产(缴费上万),这些都是要注意的而本地的话,不用顾虑这些,而且也没有任何费用
参考资料
remotely-save插件Bug相关话题- 产品
- obsidian-image-auto-upload-plugin:Obsidian上传图床的插件,依赖
PicGo - PicGo下载链接
- 阿里OSS-SDK:SDK 文档
- obsidian-image-auto-upload-plugin:Obsidian上传图床的插件,依赖
- 搭建图床教程
- 【Obsidian绝配!】为你的OB搭建专属图床,保姆级教程!:PicGo+腾讯云OSS
- 阿里云OSS PicGo 配置图床教程 超详细:阿里OSS也可参考这篇
OSS搭建
OSS搭建因为之前讲过,这里不再赘述(详情参考:Obsidian同步方案)
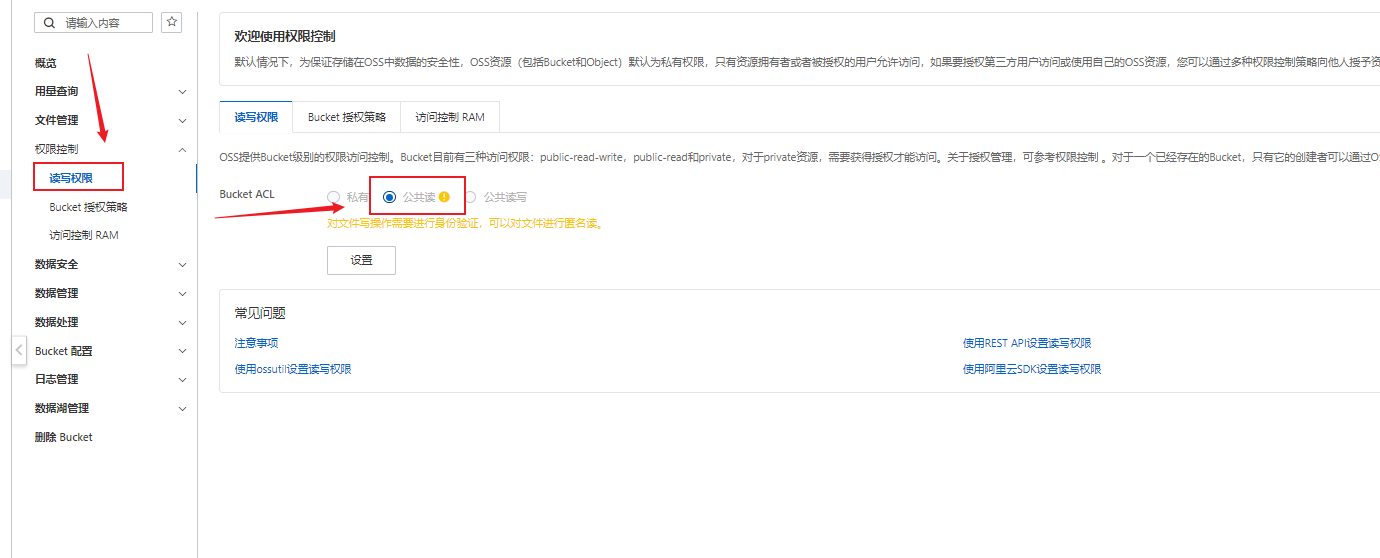
需要注意的是,由于需要访问(浏览图片),所以Bucket的授权有所不同,也不能完全参考我上篇
其他步骤可以相同,但Bucket的读写权限需要设置为公共读,否则浏览不出来
这是需要注意的地方,也是参考资料3.2所没有讲到的,当然 OSS 搭建也可以参考其教程,讲的蛮详细的
PicGo
安装
先安装PicGo,安装链接见参考资料2.2
不管是Obsidian的插件还是Typora,两者的图片上传都依赖PicGo
注意事项
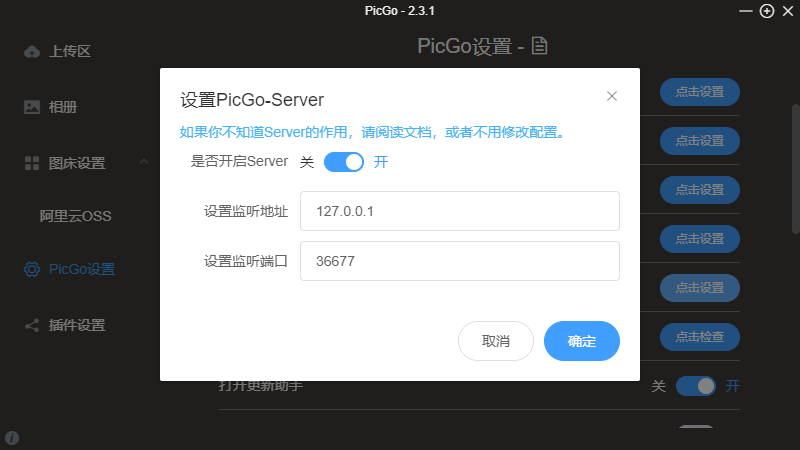
但是有一点要注意,个人安装
2.3.1,监听端口是366771我不确定是否是否手误按到
1打上去了,还是作者改了默认端口
作者改的话,也没想明白,为啥改…
Typora和Obsidian都是采用36677Typora还无法改监听端口,如果发现是366771,那么必须要改回来在
Picgo设置的Server中设置
配置
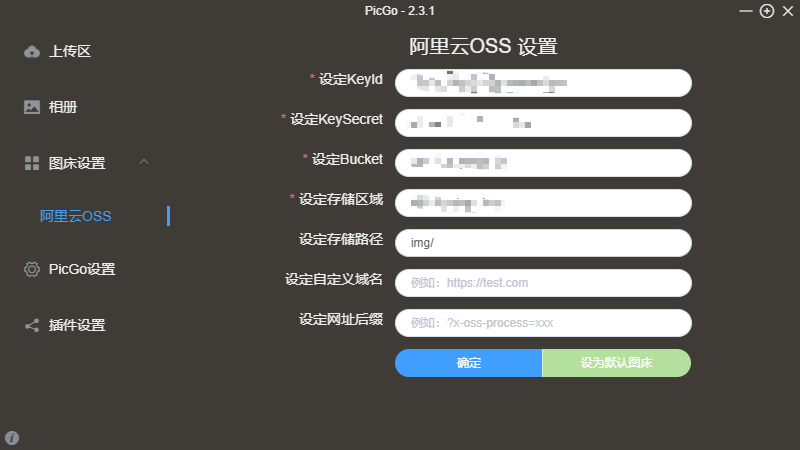
OSS配置完后用户后,会得到一个AccessKey ID和AccessKey Secret
需要在PicGo这里填写
设定
KeyId:填写OSS用户的AccessKey ID设定
KeySecret:填写OSS用户的AccessKey Secret设定
Bucket:填写桶的名称,可以在概览中找到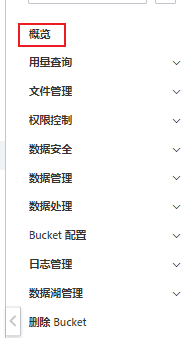
设定存储区域:也是在概览中找到,找到ECS 的经典网络访问(内网)对应的Endpoint(地域节点),然后只要前面的区域,例如个人是
oss-cn-shenzhen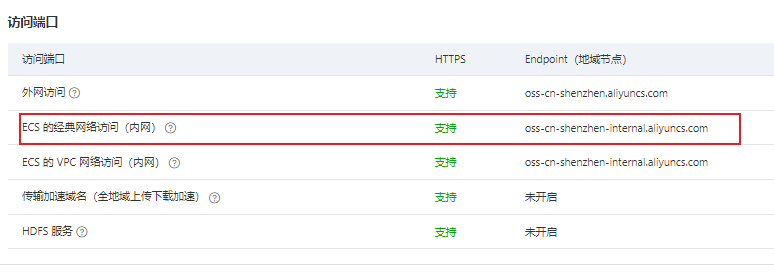
设置存储路径:根据自己需要,如果要放根目录,就写
/,如果要放一个文件夹中就文件夹名字/
其他空着就好
Obsidian 使用图床
前提条件:已经安装好Picgo,并且启动了软件
安装插件:
Image auto upload plugin,所有选项保持默认即可之后所有粘贴的图片就会自动调用
PicGo进行上传,并且将链接转换为图床链接
存量同步
注意事项
这种涉及对 Obsidian 库大批量文件操作的,都必须将库先备份一份!!!
虽然说博主运行没有问题,但不保证每个人运行都没有问题,例如编码格式不符合,例如突然断电等等
不管是运行这个脚本还是其他,记得养成习惯,大批量操作进行备份一份总没有错
上面安装后,只能对新建的文件进行图床链接的转换,现有的存量笔记则没有办法
虽然Image auto upload plugin提供了一个upload all images选项,但是只对一个笔记有效
upload all images操作方法
- Ctrl / Command + P:打开命令模式
- 输入
upload,自动出现upload all images,选择即可
不可能一个个点过去执行吧,太傻,这不是程序员该做的事情doeg
写个脚本,对现有的markdown文件进行链接的转换
- 该脚本会自动匹配两种格式的链接,将其转换成图床链接
- 标准Markdown格式:
 - wiki格式:
![[]]
- 标准Markdown格式:
- 对于21行的一个说明,如果文件链接有空格,Obsidian不会显示的,所以必须要转义,这里空格转换成了
%20
import os
import re
def markdown_match(match):
"""处理标准图片链接"""
image_title = match.group(1)
image_link = match.group(2)
image_name = os.path.basename(image_link) # 提取图片名称
image_name = image_name.replace("assets/", "")
replaced_link = f""
return replaced_link
def wiki_match(match):
"""处理wiki图片链接"""
image_name = re.sub(r'[![\]]', '', match.group(0))
mark_image_name = image_name.split('.')[0]
image_url = image_name.replace(' ', '%20')
replaced_link = f""
return replaced_link
def replace_image_links(md_file):
"""替换链接"""
with open(md_file, "r", encoding='utf-8') as f:
content = f.read()
# 匹配标准图片写法:![]()
pattern = r"!\[(.*?)\]\((.*?)\)"
replaced_content = re.sub(
pattern, lambda match: markdown_match(match), content)
# 匹配wiki写法:![[]]
pattern_wiki = r'(?:!\[\[(.*?)\]\])'
replaced_content = re.sub(
pattern_wiki, lambda match: wiki_match(match), replaced_content)
with open(md_file, "w", encoding='utf-8') as fw:
fw.write(replaced_content)
def main(folder_path):
# 遍历某个文件夹下的所有md文件
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith(".md"):
replace_image_links(os.path.join(root, file))
if __name__ == "__main__":
folder_path = r"D:\Software\0_笔记库" # 替换成你要遍历的文件夹路径
picGo_url = '' # 图床链接
main(folder_path)
Typora 使用图床
前提:已经安装好Picgo,并且启动了软件
切换成下面的配置即可
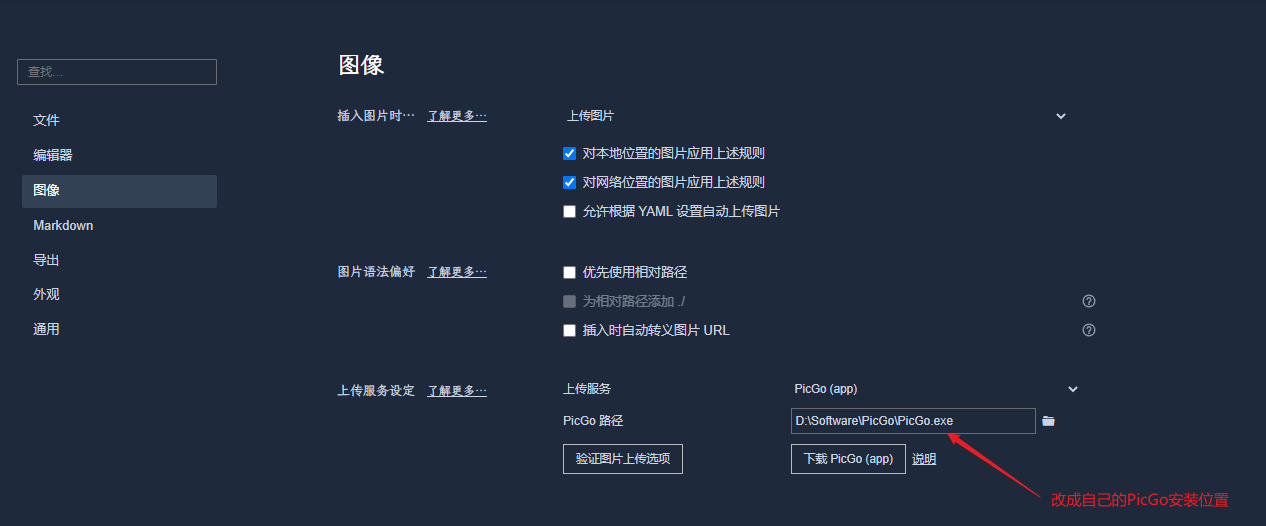
之后点击验证图片上传选项,一般配置好都没有什么问题,会提示上传成功(上传2张Typora的小图,用于测试的)
清理图片
原先图片在附件文件夹,清理非常方便,安装个插件Clear Unused Images即可
点击侧边的按钮,就会自动清理没有引用的图片
例如:笔记A引用了图片A,如果笔记A删除了,那么图片A,相当于没有被任何文件引用,占用空间
现在采用图床就面临这个问题,如果笔记删除了,但图床中其实还存在对应的图片
虽然说也可以不删除,但个人凭感觉做事,能删除就删除吧~,算是整理的一环
写脚本,思路如下
- 获取
Markdown所有引用的图片链接,得到列表A - 获取所有
OSS中的图片链接,得到列表B - 通过列表B-列表A,得到两者的差集,多出来的及没有被引用的图片(笔记删除,图片没删)
- 调用SDK,对没有引用的图片进行批量删除
其中2、4步骤需要调用阿里 OSS 的 SDK,具体参考参考资料2.3
Python 先安装 oss2
直接使用 pip 安装即可
pip install oss2
代码如下:
# -*- coding: utf-8 -*-
import oss2
import os
import re
def check_OssFile(file_name):
"""检测文件是否存在"""
exist = bucket.object_exists(f'img/{file_name}')
return True if exist else False
def del_OssFile(file_name):
"""删除单个文件"""
if check_OssFile(file_name):
bucket.delete_object(f'img/{file_name}')
else:
print('未找到文件')
def del_OssFileList(list_obj):
"""删除多个文件"""
result = bucket.batch_delete_objects(list_obj)
# 打印成功删除的文件名。
print('\n'.join(result.deleted_keys))
def get_ObsidianImage() -> list:
"""获取Obsidian所有图片链接"""
ob_list = []
# 遍历某个文件夹下的所有md文件
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.endswith(".md"):
with open(os.path.join(root, file), "r", encoding='utf-8') as f:
content = f.read()
pattern = re.compile(r"!\[(.*?)\]\((.*?)\)")
for i in pattern.findall(content):
ob_list.append(i[1].replace(
'https://baidu.com/', '').replace('%20', ' '))
return ob_list
def get_OssImgae() -> list:
"""列举文件夹下的所有文件"""
oss_list = [obj.key for obj in oss2.ObjectIterator(bucket, prefix='img/')]
return oss_list
def main():
ob = get_ObsidianImage()
oss = get_OssImgae()
del_list = list(set(oss) - set(ob)) # 待删除列表
# 批量删除文件
del_OssFileList(del_list)
if __name__ == '__main__':
folder_path = r"D:\Software\0_笔记库" # 替换成你要遍历的文件夹路径
# oss对象初始化
auth = oss2.Auth('AccessKey ID',
'AccessKey Secret')
bucket = oss2.Bucket(auth, 'https://oss-cn-shenzhen.aliyuncs.com', '桶名称')
main()
- 40行:将
'https://baidu.com/'替换为自己的图床链接(这里隐私需要,所以个人替换为百度链接) - 66行:填写Obsidian库的绝对位置
- 69行:填写自己用户的
AccessKey ID和AccessKey ID - 71行:填写自己的区域节点和桶名称
其他额外说明
由于Obsidian和Typora设置好后,粘贴得到的都是标准Markdown链接,既![]()
所以这个脚本没有做wiki链接的匹配,既![[]]
由于上面Obsidian存量同步的原因,链接中的空格都被转换成%20,所以这里必须要转换回来
否则两者对比无法进行判断,例如:
图传是:paste image 123
本地是:paste%20image%20123